


Nitric’s core value is language-agnostic abstraction from cloud infrastructure. We accomplish this with a set of easy to learn, consistent APIs including storage, documents, events, queues, and more.
The question for us was what technology to use to communicate between applications and the Nitric service that provides those decoupled APIs.
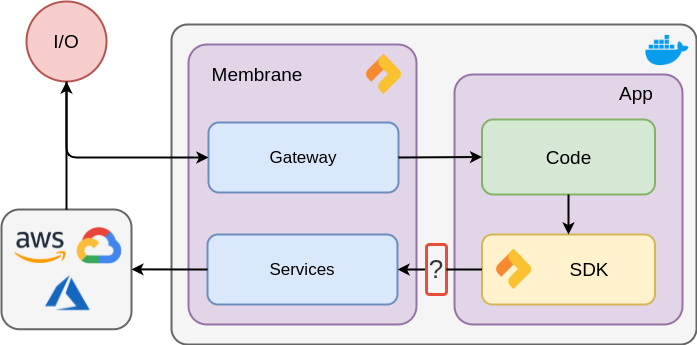
(Check out our core github repo for more info on how the nitric membrane works)
Ideally, this technology would:
- Minimize overhead
- Be strongly contract-driven
- Provide tooling for client/server generation
- Have awesome community support
Enter gRPC
Open-sourced in 2016 by Google, gRPC is quickly growing in popularity as a tool to build APIs, especially for microservices, container sidecars and service-to-service communication.
Preliminary research into gRPC revealed several advantages over familar REST/HTTP based alternatives, such as OpenAPI (Swagger). We began our foray into gRPC by creating a simple abstraction that would allow developers to read contents from blob storage both locally and across clouds.
syntax=”proto3”;
service Storage {
rpc Read(ReadRequest) returns (ReadResponse);
}
message ReadRequest {
string bucket = 1;
string key = 2;
}
message ReadResponse {
bytes content = 1;
}
From memory it looked something like this, definitely should have streamed the response, but we were still learning 😅
That was it, we generated a simple server in Go (more on our choice of GoLang in a later blog) and started testing using BloomRPC (it's kind of like Postman for gRPC), once we had pluggable working implementations across clouds (GCP and AWS at the time) we were hooked!
From there it grew, first generating basic clients for various languages (Node.js and Python), adding more methods and service types, and eventually writing idiomatic wrappers for improved developer experience over the auto generated clients.
There were some teething issues we had to work through (the default python code gen being one - btw, huge shoutout to the team working on betterproto, it's awesome!). But all in all, from our first contact with gRPC, we could easily see how it checked all the boxes for what we needed.
Fast & Efficient
gRPC brings together the efficient connection management of HTTP/2 with the compactness of Protocol Buffers for data serialization. This greatly reduces overhead when compared to HTTP/1.1 and traditional text based serialization such as JSON.
HTTP/2 vs HTTP/1.1
gRPC lets us take advantage of significant performance improvements made to HTTP/2 over HTTP/1, specifically with connection reuse and streaming. HTTP2 can send multiple requests/responses using a single connection where HTTP1 must re-establish a new TCP connection per request/response, reducing connection brokering between two systems improves overall latency and overhead.
I won’t rehash performance comparisons between the two, since many already exist, instead I'd recommend taking a look at this article from DigitalOcean and another from css-tricks for a detailed breakdown on performance.
Protocol Buffers v. JSON
Moving data over the wire takes time, the larger the payloads the more time they take. This is where Protocol Buffers shine over traditional text based serialization such as JSON.
Consider a simple payload represented in JSON:
{
"name": "Tim"
}
In Protocol buffers we could define the message as:
message Person {
string name = 1;
}
Translating the above to an on onwire translation gives this result:
0x0a 0x03 [0x54 0x69 0x6d] (brackets here encapsulate the payload).
Note: checkout Google's developer docs to see a detailed explanation of encoding in gRPC
If we use the above payload, the 'weight' of each representation on the wire is:
JSON: 14 Bytes
Proto: 5 Bytes
On the wire the proto payload is only 35.7% the size of the JSON representation!
Also, depending on how your JSON schema is designed, binary serialization will generally scale far better for large payloads without sacrificing the comprehensibility of your contract (e.g. truncating key names to save bytes).
Streaming was also a big factor for Nitric, our Nitric Server is built on gRPC streams, which we'll be sure to cover in a future blog.
Clear Cut Contracts
Another strength of gRPC is the DSL used to create contracts. It's clean, readable and easy to document, particularly in contrast to OpenAPI (formerly Swagger) specs.
Proto3 vs OAI3
Protocol Buffers
service User {
rpc Create(CreateUserRequest) returns (CreateUserResponse);
rpc Read(ReadUserRequest) returns (ReadUserResponse);
}
message User {
string id = 1;
string email = 2;
string name = 3;
}
message CreateUserRequest {
User user = 1;
}
message CreateUserResponse {
String id = 1;
}
message ReadUserRequest {
string id = 1;
}
message ReadUserResponse {
User user = 1;
}
OpenAPI
openapi: 3.0.0
info:
version: 1.0.0
title: User API
description: User API
paths:
/user:
post:
operationId: user-create
description: Creates and persists a new user
responses:
'200':
description: Successful response
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/User'
/user/{id}:
get:
operationId: user-get
parameters:
- in: path
name: key
schema:
type: string
description: Retrieve an existing user by its ID
responses:
'200':
description: Successful response
components:
schemas:
User:
type: object
properties:
id:
type: string
email:
type: string
name:
type: string
The improvement in readability is pretty staggering. While OpenAPI 3 is extremely flexible and encompasses most capabilities of HTTP, the opinionated nature of proto3 and gRPC gives it an edge when it comes to simplicity, enhancing readability.
Lastly, because Protocol Buffers use indexes over keys for data serialization, detecting potentially breaking changes in contracts is much easier. This is evident in the wide range of tooling that helps facilitate contract validation and linting for proto files such as Buf. Allowing for breaking change detection as part of CI pipelines can assist in blocking changes that will alter the backwards compatibility of a contract.
Tooling and community
Despite only being open-source since 2016, the gRPC community has grown rapidly. There's an expanding ecosystem of implementations and code generation for a variety of languages and other communities.
Protoc (the gRPC compiler) and surrounding tooling played a large part in the decision to use gRPC for Nitric. The ability to generate clients which connect to Nitric’s unified APIs from proto contracts was critical to our multi-language support and automating these builds ensures our base SDKs never get left behind when improvements are made.
In our current CI/CD pipelines we automatically produce base client libraries for the Nitric API on every publish of the core framework.
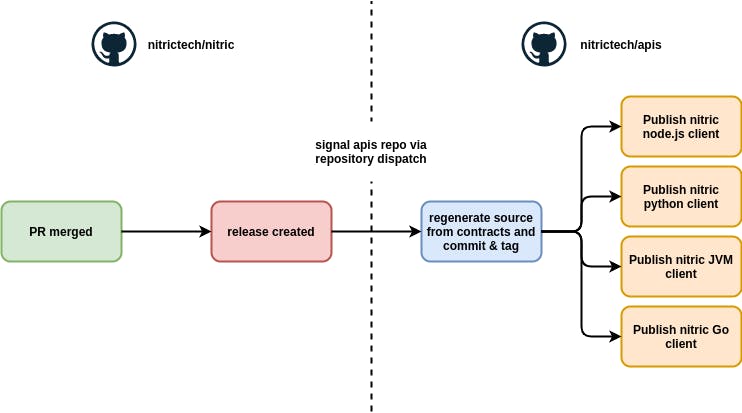
You can see how we built this automation in our GitHub repos using GitHub Actions workflows. https://github.com/nitrictech/nitric, https://github.com/nitrictech/apis
To see how we consume these auto-generated API clients and wrap them into more language idiomatic SDKs, check out our SDK projects for our supported languages:
- https://github.com/nitrictech/node-sdk
- https://github.com/nitrictech/python-sdk
- https://github.com/nitrictech/java-sdk
- https://github.com/nitrictech/go-sdk
Conclusion
This isn't an argument that gRPC is a silver bullet for all things API. When it comes to building and designing services, there is no one size fits all and needs/constraints will differ from project to project. If you have a project with similar requirements to Nitric, or simply want to create a language-agnostic programmatic wrapper for a set of tooling, then I would highly recommend trying a PoC with gRPC. Getting started is easy just check out the docs. You could even use Nitric as inspiration; our core and unified APIs are fully open source!

